
The Labyrinth of Financial Identifiers: A Core Challenge for Asset Managers
Financial institutions, particularly asset management firms, operate within a complex data ecosystem characterised by a multitude of systems, diverse asset classes, and evolving regulatory landscapes. A foundational challenge within this environment is the inconsistent and often siloed management of financial instrument identifiers. This section explores the typical scenario and its far-reaching consequences.
A. A Case Study in Data Chaos
Consider a mid-sized asset management firm based in Frankfurt. Like many of its peers, this firm comprises various specialised departments: Portfolio Management, Risk Analysis, Operations, Compliance, and Client Reporting. Each department, driven by its unique functional requirements, often relies on distinct software solutions and data feeds. Portfolio Management might utilise a system that primarily employs Bloomberg Tickers (BBID) and SEDOLs for tracking UK-listed equities. Simultaneously, the Risk department’s analytical platform may predominantly ingest data keyed by International Securities Identification Numbers (ISINs) to ensure broad market coverage. The Operations team, responsible for trade settlement, frequently encounters CUSIPs for North American securities and a variety of national identifiers for instruments from other regions.
This departmental specialisation, while logical from an operational standpoint, frequently leads to the creation of data silos. Different teams collect, manage, and store their data separately, often with limited interoperability. Data silos can mirror organisational structures, and are often reinforced by conflicting data management approaches or the historical autonomy of departments in selecting their tools. The result is a fragmented data landscape where a single security might be represented by multiple, inconsistent identifiers across the firm. This scenario is not unique to one firm; the broader financial industry grapples with the “varying ways to identify individual securities,” often influenced by “national specificities” such as SEDOL for London Stock Exchange instruments or CUSIP for North American securities. The absence of a universally adopted internal standard for linking these disparate identifiers makes comprehensive data integration a formidable task.
This proliferation of identifiers often arises not from deliberate design but from an accumulation of historical system choices, mergers and acquisitions, and the adoption of best-of-breed applications for specific functions. Each new system or data feed introduces its “native” identifiers. Without a proactive, overarching data strategy, this leads to what can be termed “accidental complexity”, a situation where the data environment becomes progressively harder to manage, not due to the inherent complexity of the financial instruments themselves, but due to the accumulated inconsistencies in how they are identified and tracked. Overcoming this requires more than isolated technical fixes; it necessitates a strategic, firm-wide commitment to data harmonisation and architectural coherence.
B. Consequences of Inconsistent Identifiers: Operational Drag, Amplified Risk, and Stifled Innovation
The lack of a unified approach to security identification has profound and detrimental consequences for financial firms. These extend beyond mere technical inconvenience, impacting operational efficiency, risk management, regulatory compliance, and the ability to innovate.
Operational Inefficiency: A primary consequence is significant operational drag. Teams expend considerable effort on manual data reconciliation, attempting to match securities across different reports and systems based on a patchwork of identifiers. This leads to increased data preparation times for critical reports, a higher propensity for errors in data processing, and ultimately, reduced productivity. Instead of focusing on value-added analysis, skilled personnel are often mired in the laborious task of data cleansing and alignment.
Increased Risk Exposure: Inconsistent identifiers severely hamper the ability to aggregate positions and exposures accurately. For a risk management function, obtaining a timely and unified view of the firm’s total exposure to a specific issuer, security, or asset class becomes a complex undertaking. This can obscure true risk concentrations, whether market risk, credit risk, or counterparty risk. The Great Financial Crisis of 2007-09 underscored the critical importance of reliable, disaggregated data for identifying financial stability risks. Without consistent identification, the ability to generate such disaggregated views is fundamentally compromised.
Impaired Decision-Making: The quality of business intelligence and analytics is directly tied to the quality of underlying data. When data is fragmented and riddled with inconsistencies, the reliability of analytical outputs diminishes. Strategic decisions, from asset allocation to new market entry, may be based on incomplete or flawed data, potentially leading to suboptimal outcomes. Centralised, high-quality data, on the other hand, demonstrably improves decision-making capabilities.
Compliance Challenges: Regulatory reporting requirements, such as those mandated by MiFID II or EMIR, often demand precise and consistent identification of financial instruments. Firms struggling with identifier inconsistencies face significant challenges in meeting these obligations accurately and efficiently, potentially leading to non-compliance and regulatory penalties.
Hindered Innovation: The ability to innovate, be it developing new financial products, implementing advanced analytical techniques like AI and machine learning, or rapidly integrating new data sources, is severely constrained by a fragmented data foundation. Each new initiative requires substantial data integration effort, increasing costs and time-to-market.
These issues create a self-perpetuating cycle of data fragmentation. Inconsistent identifiers lead to data quality problems. Poor data quality necessitates complex, often manual, reconciliation processes. These processes are inherently error-prone and time-consuming, further eroding trust in the data and discouraging investments in data standardisation or centralisation. This vicious cycle makes it progressively harder to escape the mire of data inconsistency without a fundamental architectural rethink. A reactive, patch-based approach to fixing data discrepancies proves unsustainable; a proactive, architectural solution is imperative.

The North Star: Advocating for an ID-First Data Architecture
To navigate the complexities born from identifier proliferation, a paradigm shift in data architecture is required. The “ID-First” approach offers a robust strategy to instil order and unlock the true value of financial data.
A. Defining the “ID-First” Principle in Data Modelling
The “ID-First” (also referred to as “identifier-first” or “identifier-centric”) principle in data modelling dictates that the establishment and consistent use of a unique, persistent, and centrally managed identifier for core business entities is paramount. In the context of financial services, this core entity is often the financial security. This central identifier serves as the primary key in master data tables and acts as the definitive linchpin for joining and integrating data from disparate source systems. All other identifiers encountered in source systems (e.g., SEDOL, CUSIP, vendor-specific tickers) are then mapped to this central, universal ID.
This approach aligns with fundamental data warehousing principles that aim to integrate data from various sources into a cohesive, query-optimised format. While specific schema design methodologies like those for relational databases or JSON structures emphasise the role of identifiers for uniqueness and organisation, the ID-First principle elevates this concept to an architectural strategy. It posits that the identifier is not merely an attribute but the cornerstone around which the data model is constructed.
Adopting an ID-First methodology inherently compels an organisation to establish clear data governance practices. The creation, maintenance, and lifecycle management of this master identifier and its associated descriptive attributes must be rigorously defined and controlled. This shifts the organisational focus from reactively reconciling a multitude of disparate identifiers to proactively managing a single, authoritative source of identification. This proactive stance is a hallmark of mature data governance and is essential for building trust and reliability in the enterprise data landscape. Consequently, the implementation of an ID-First architecture is as much a data governance and business process transformation as it is a technical undertaking, requiring strong data stewardship and clear lines of responsibility.
B. The Power of a Universal Identifier: FIGI, ISIN, or an Internal Master ID?
The selection of the central universal identifier is a critical decision in an ID-First strategy. Several candidates exist, each with its own strengths and considerations:
- ISIN (International Securities Identification Number): ISINs are widely adopted and globally recognised, particularly for facilitating cross-border trading of listed securities. An ISIN is a 12-character alphanumeric code comprising a two-letter country code, a nine-character National Securities Identifying Number (NSIN), and a final check digit. While ISINs offer broad coverage for many exchange-traded instruments, they may not encompass all asset classes (e.g., certain OTC derivatives, loans) or provide the level of granularity required for some analytical use cases, such as exchange-level identification for equities traded on multiple venues. In some jurisdictions, the ISIN structure incorporates local identifiers like CUSIP within the NSIN portion.
- FIGI (Financial Instrument Global Identifier): FIGI is an open, non-proprietary standard designed by Bloomberg and now managed by the Object Management Group (OMG). It aims to provide highly granular identification for a wide array of financial instruments, including equities, debt, options, futures, and more, often down to the specific trading venue. Proponents highlight FIGI’s benefits in enhancing transparency, improving risk management, and increasing operational efficiency due to its open nature and detailed structure. The Financial Data Transparency Act (FDTA) in the U.S. has also signalled a regulatory push towards open, non-proprietary identifiers like FIGI for financial reporting. However, the potential mandating of FIGI has sparked considerable industry debate, with concerns raised about the costs, complexities, and disruptions associated with transitioning from long-established identifiers like CUSIP and ISIN. Many market participants argue that a robust cost-benefit analysis is lacking and that existing identifiers are deeply embedded in market infrastructure.
- Internal Master ID (Proprietary Universal ID): An organisation can opt to create and manage its own internal master identifier. This approach offers maximum flexibility and control, allowing the identifier system to be precisely tailored to the firm’s specific data models, business logic, and analytical requirements. However, developing and maintaining an internal ID system requires significant investment in master data management (MDM) practises, robust governance, and technology. A critical risk is that if an internal ID is not meticulously and comprehensively mapped to global standard identifiers (like ISIN and FIGI), it can inadvertently become another silo, perpetuating the very problem it aims to solve. Best practises dictate storing source system identifiers for cross-referencing but using a distinct, mastered ID as the primary key.
The following table provides a comparative overview:
Table 1: Comparative Analysis of Key Financial Identifiers
Feature | ISIN | SEDOL | CUSIP | FIGI | Internal Master ID |
Issuing/Gov. Body | National Numbering Agencies (NNAs) under ANNA | London Stock Exchange | CUSIP Global Services (S&P Global) | Object Management Group (OMG) / Bloomberg (as RA) | Organisation Specific |
Cost (Typical) | Varies by NNA; usage fees may apply | Licence fees apply | Licence fees apply | Open standard (no direct licence for ID itself); data access for enrichment may have costs. | Internal development & maintenance costs |
Coverage (Assets) | Broad for listed securities; some gaps for OTC, loans | Primarily UK & Irish equities, some fixed income | Primarily North American securities | Very broad: equities, debt, derivatives, currencies, etc. | Defined by the organisation’s scope |
Coverage (Geo) | Global | Primarily UK & Ireland | North America | Global | Defined by the organisation’s scope |
Granularity | Instrument level; sometimes exchanged via NNA practises | Instrument level | Instrument level | High: can go to market/exchange level, specific share class, maturity, strike, etc. | Customisable to any required granularity |
Openness | Standardised (ISO 6166), but NNA issuance can vary; CUSIP-based in US | Proprietary | Proprietary | Open Data Standard (MIT Licence). | Proprietary to the organisation |
Key Pros | Widely adopted, good for cross-border listed instruments | Established in UK markets | Established in North American markets | Granular, open, broad asset coverage, supports interoperability, no direct ID cost | Full control, customisable, tailored to specific needs |
Key Cons/Challenges | May lack granularity, not all asset classes fully covered | Limited geographic/asset coverage, cost | Limited geographic coverage, cost | Adoption challenges, potential transition costs from ISIN/CUSIP, ecosystem maturity varies. | Risk of isolation, high governance overhead, build cost |
Ultimately, no single external identifier may perfectly serve all purposes for every financial institution. The true “universality” in an ID-First strategy often emerges not from the exclusive adoption of one global standard as the sole internal primary key, but from the establishment of a robust and comprehensive mapping infrastructure. The chosen central identifier—whether it’s an established global standard like FIGI or a meticulously governed internal ID—acts as the “Rosetta Stone,” enabling the translation and linkage of all other relevant internal and external identifiers. Therefore, the design, implementation, and ongoing maintenance of the mapping tables and associated processes are as crucial to the success of an ID-First architecture as the selection of the central identifier itself. The strategy should be to centralise the concept of a unique security and then diligently map all specific instances and their varied identifiers to it.
C. Benefits of an ID-Centric Approach for Financial Data Warehouses
Adopting an ID-centric approach, underpinned by a universal identifier, yields substantial benefits for financial data warehouses and the analytical ecosystems they support:
- Improved Data Quality and Consistency: By establishing a single, authoritative identifier for each security, firms can create a “single source of truth” for security master data. This dramatically reduces discrepancies, errors, and ambiguities that arise from managing multiple, inconsistent identifiers. Data quality is enhanced because all attributes and associated data for a given security are linked through one master key.
- Enhanced Analytics and Business Intelligence: With a consistent universal ID, data aggregation across different portfolios, business units, or source systems becomes significantly simpler and more reliable. Analysts can perform cross-functional analyses with greater confidence, leading to more accurate insights for investment strategy, risk management, and operational improvements.
- Increased Operational Efficiency: The need for manual reconciliation of security identifiers is greatly diminished, freeing up valuable resources. Data integration processes are streamlined, and the time required to generate reports and respond to ad-hoc queries is reduced. This translates into lower operational costs and faster access to information.
- Stronger Data Governance and Compliance: An ID-First model promotes clearer data ownership and stewardship for security master data. Auditing data lineage and usage becomes more straightforward. Crucially, the ability to consistently identify securities across all datasets improves a firm’s capacity to meet regulatory reporting mandates accurately and efficiently.
- Simplified Data Architecture: The overall complexity of the data architecture is reduced. Data pipelines become less convoluted as they can rely on a common identifier for integration. Onboarding new data sources or systems is also simplified, as the primary task becomes mapping the new system’s identifiers to the existing universal ID framework.
This ID-First architecture serves as a foundation for greater agility and future-proofing. By abstracting the core concept of a “security” through a stable, universal identifier, the data architecture becomes more resilient and adaptable to change. When new source systems are introduced, or if new market identifiers gain prominence, they can be integrated by updating the mapping layer without necessitating fundamental changes to downstream data consumption patterns or core analytical models. Similarly, if the firm decides to evolve its primary external reference standard (e.g., increasing reliance on FIGI alongside ISIN), this transition can be managed within the identifier mapping system, minimising disruption to the broader data ecosystem. Thus, an ID-First approach is not merely about solving current data integration challenges but also about building a more robust and adaptable data foundation capable of weathering future market, technological, and regulatory shifts.
Implementing an ID-First Architecture in Snowflake: A Practical Guide
Snowflake’s cloud data platform provides a powerful and flexible environment for implementing an ID-First data architecture in financial services. Its unique features can significantly simplify the challenges associated with managing diverse financial identifiers.
A. Snowflake as the Foundation for Modern Financial Data Platforms
Snowflake’s architecture is inherently well-suited for the demands of a modern financial data platform. Its cloud-native design offers separation of storage and compute, enabling independent scaling of resources to match workload demands, which is crucial for handling variable data ingestion and complex analytical queries common in finance. The platform’s robust support for semi-structured data (e.g., JSON, Avro, Parquet) facilitates the ingestion of diverse data feeds from various sources without requiring extensive upfront transformation. Furthermore, Snowflake’s data sharing capabilities allow secure and governed collaboration with external partners or internal departments, while its growing ecosystem, including Snowpark for advanced analytics and Python User-Defined Functions (UDFs), empowers sophisticated data processing directly within the warehouse.
The dynamic nature of financial identifiers, new issues, corporate actions causing changes, evolving vendor symbologies, requires a platform that can adapt. Snowflake’s capabilities, such as flexible schema management (schema-on-read for initial ingestion), the VARIANT data type for handling diverse raw data structures, and efficient processing of complex joins and UDFs, make it an ideal candidate for managing the intricate mapping and cleansing processes inherent in an ID-First system.
Features like Time Travel, which allows access to historical states of data, can also be invaluable for auditing changes to security master data or identifier mapping tables, providing a safety net and enhancing data governance. The choice of data platform is therefore not incidental; specific Snowflake features actively lower the technical barriers to implementing and maintaining a sophisticated and resilient ID-First architecture.
B. Designing Dimension Tables for Securities: Keyed by a Universal ID
At the heart of an ID-First architecture in Snowflake lies a well-designed dimension table for securities, often named DimSecurity or SecurityMaster. This table serves as the central, authoritative repository for all security-related attributes.
- Primary Key: The primary key for DimSecurity should be the chosen MasterSecurityID. This could be an internally generated universally unique identifier (UUID) or, if the organisation fully commits to an external standard as its core, a carefully governed identifier like FIGI. It is crucial that this MasterSecurityID is unique and persistent.
- Key Attributes: This dimension table will house a comprehensive set of attributes describing each security. These include:
- Common External Identifiers: Fields for ISIN, FIGI, SEDOL, CUSIP, BloombergTicker, etc. These are stored as descriptive attributes, facilitating lookups and cross-referencing, but they are not the primary key.
- Descriptive Attributes: SecurityName, SecurityDescription, AssetClass, AssetType, IndustrySector, CountryOfIssue, CurrencyOfDenomination.
- Issuer Information: An IssuerID (a foreign key referencing a DimIssuer table, which would contain details like IssuerName, LegalEntityIdentifier (LEI), etc.).
- Terms and Conditions: For debt instruments, this might include MaturityDate, CouponRate, DayCountConvention; for options, StrikePrice, ExpirationDate, OptionType.
- Market Data Links (Optional): While core market data like prices might reside in fact tables or specialised market data tables, DimSecurity could include references or flags related to pricing sources or exchanges.
- Corporate Actions & Cash Flows: Information related to past or upcoming corporate actions and expected cash flows can also be linked or directly included depending on the design complexity.
- Slowly Changing Dimensions (SCDs): Financial instrument attributes can change over time (e.g., a change in credit rating, a new name after a merger). To maintain historical accuracy, DimSecurity should be designed to handle these changes, typically using an SCD Type 2 approach. This involves adding ValidFromDate and ValidToDate columns (or version numbers and an IsCurrent flag) to track the history of attribute changes for each MasterSecurityID. Snowflake’s dynamic tables can be a useful feature for implementing and managing SCDs efficiently.
The DimSecurity table, keyed by the MasterSecurityID, evolves beyond being just a “golden record.” It becomes a “golden profile,” consolidating not only the authoritative attributes of a security but also serving as the central hub for linking to all known source-system identifiers and the security’s historical states. This richness is fundamental to powering accurate, time-consistent analytics and reporting. Populating and maintaining DimSecurity and its associated mapping tables is a core Master Data Management (MDM) function, critical to the sustained success of the ID-First architecture.
A conceptual schema diagram illustrating these core relationships might look as follows:
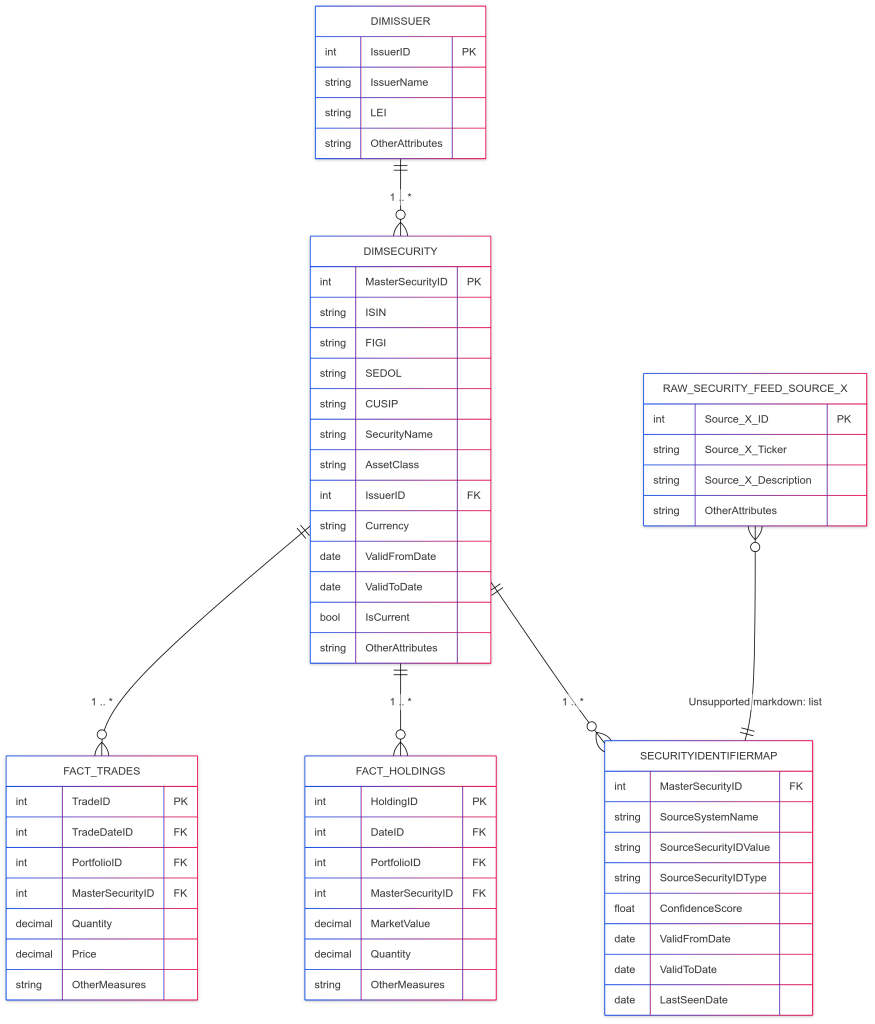
Diagram Description:
- DimSecurity: The central dimension table, keyed by MasterSecurityID. Contains various standard identifiers (ISIN, FIGI, etc.) as attributes, along with descriptive information and SCD columns. It has a foreign key to DimIssuer.
- SecurityIdentifierMap: A mapping table linking various source system identifiers (SourceSecurityIDValue from different SourceSystemName and SourceSecurityIDType) to the MasterSecurityID. This table is crucial for reconciliation.
- Raw_Security_Feed_Source_X: Represents a staging area or external table for an incoming data feed, containing its native identifiers.
- DimIssuer: Dimension table for issuers, linked to DimSecurity.
- Fact_Holdings / Fact_Trades: Example fact tables that link to DimSecurity via MasterSecurityID, demonstrating how the universal ID simplifies joins for analytical queries.
This structure, often part of a broader star or snowflake schema, ensures that the MasterSecurityID is the consistent point of reference across the data warehouse.
C. Strategic Use of Mapping Tables for Identifier Reconciliation
Mapping tables are the engine of identifier reconciliation in an ID-First architecture. A typical mapping table, let’s call it SecurityIdentifierMap, would link various incoming identifiers from different source systems to the single MasterSecurityID.
- Structure: Key columns in SecurityIdentifierMap would include:
- MappingID (PK, optional, for unique row identification within the map itself)
- SourceSystemName (e.g., ‘Bloomberg’, ‘Refinitiv’, ‘InternalSystemA’)
- SourceSecurityIDValue (the actual identifier string from the source, e.g., ‘037833100’, ‘US0378331005’)
- SourceSecurityIDType (e.g., ‘CUSIP’, ‘ISIN’, ‘SEDOL’, ‘BBG_TICKER’)
- MasterSecurityID (FK, referencing DimSecurity.MasterSecurityID)
- ConfidenceScore (a metric indicating the certainty of the mapping, useful for automated suggestions)
- MappingSource (e.g., ‘SystemRule’, ‘DataVendorXRef’, ‘ManualStewardship’)
- ValidFromDate, ValidToDate (to track the effective period of the mapping)
- LastSeenDate (when this source identifier was last observed)
- Purpose and Maintenance: This table is continuously updated. Mappings can be created and maintained through a combination of automated processes (e.g., rules-based matching on known relationships, fuzzy logic for suggestive matches) and manual data stewardship. For instance, a new security feed might introduce identifiers not yet in the map; an automated process could flag these, and a data steward would then validate and confirm the mapping to the correct MasterSecurityID. The Goldman Sachs Security Master, for example, heavily relies on “symbology” for such identifier mapping, underscoring its industry importance.
Identifier mappings are not static; they are dynamic, living entities. New securities are issued, existing identifiers change due to corporate actions (e.g., mergers, spin-offs resulting in new CUSIPs for existing entities), data vendors update their symbologies, and new data sources are onboarded. Consequently, the mapping tables must be designed for frequent updates and should include rich metadata about the mapping itself (source, confidence, effective dates). The processes governing the maintenance of these mapping tables are as critical as their structure. This includes automated discovery of potential new mappings, defined workflows for validation and approval by data stewards, and comprehensive audit trails of all changes. A modern approach to facilitate this stewardship is the use of Snowflake Native Applications with Streamlit UIs, which can provide user-friendly interfaces for business users or data stewards to manage and approve mappings directly within Snowflake.
D. Ingesting Raw Data with Inconsistent Identifiers: Leveraging Snowflake External Tables
Snowflake External Tables provide an effective mechanism for the initial ingestion of raw data from diverse source systems without immediately enforcing strict schema conformity or identifier consistency. Data files from vendors, extracts from legacy operational systems, or feeds from trading platforms can be landed in an external stage (e.g., AWS S3, Azure Blob Storage, Google Cloud Storage) and then queried via external tables as if they were native Snowflake tables.
This “schema-on-read” capability is particularly beneficial in an ID-First architecture. Raw data, with its potentially inconsistent or unrecognised identifiers, can be loaded into a staging area within Snowflake quickly and efficiently. The crucial step of identifier reconciliation against the SecurityIdentifierMap and DimSecurity can then be performed as a subsequent, controlled process within the Snowflake environment. External tables can be partitioned based on file path structures (e.g., by date or source system), which can improve query performance during the initial processing stages. Furthermore, Snowflake can automatically refresh the metadata of external tables when new files arrive in the external stage, ensuring that the ingestion pipeline is always aware of the latest data.
By employing external tables, the ingestion phase is effectively decoupled from the transformation and cleansing phases. This decoupling makes the overall data pipeline more resilient to upstream changes. If a data vendor alters its file format slightly or introduces a new, previously unseen identifier, the raw data can still be landed. The mapping and cleansing logic, executed within Snowflake, can then be adapted to handle these changes without breaking the initial ingestion flow. This approach enhances the robustness of the data pipeline and allows for more agile responses to the evolving nature of financial data sources.
E. On-the-Fly Identifier Cleansing and Validation with Snowflake
Once raw data is available (e.g., via external tables or staged in raw tables), Snowflake’s processing capabilities, particularly Python UDFs and Snowpark, can be employed for on-the-fly identifier cleansing, validation, and mapping.
Python UDFs for Normalisation and Validation. Snowflake allows users to create User-Defined Functions (UDFs) in Python, which can be executed directly within SQL queries. These are invaluable for:
- Normalising Identifiers: Applying standard formatting rules, such as converting identifiers to uppercase, removing extraneous spaces or special characters, or padding to a standard length.
- Validating Checksums: Many financial identifiers include a check digit to validate their integrity.
- ISIN Validation: ISINs use a variation of the Luhn algorithm (Modulus 10, Double-Add-Double) for their check digit. A Python UDF can implement this algorithm to verify the validity of an incoming ISIN string. Libraries like stdnum in Python offer pre-built validation for ISINs and other standard numbers.
- FIGI Validation: FIGIs also use a Modulus 10 Double Add Double technique for their check digit. The specific character-to-number conversion rules (e.g., A=10, B=11, vowels excluded) can be encoded in a Python UDF for validation.
- Implementing Fuzzy Matching Logic: For identifiers that don’t have a direct match in the SecurityIdentifierMap, Python UDFs can incorporate fuzzy matching algorithms (e.g., Levenshtein distance, Jaro-Winkler) on descriptive fields like SecurityName or IssuerName to suggest potential MasterSecurityID candidates for data steward review.
- Mapping Lookups: A Python UDF can encapsulate the logic to query the SecurityIdentifierMap table, taking a source identifier and type as input and returning the corresponding MasterSecurityID or a flag if no match is found. An example of mapping DII to UID2s via UDFs shows this pattern.
Snowpark for Complex Transformations. For more computationally intensive cleansing operations, complex rule-based mapping, or machine learning-driven identifier matching (especially when dealing with very large datasets or requiring extensive library support beyond standard Python UDFs), Snowflake’s Snowpark API is a powerful option. Snowpark allows developers to write data transformation logic using familiar DataFrame APIs in Python (or Scala/Java), which then execute on Snowflake’s distributed processing engine. This enables the development of sophisticated data pipelines for identifier resolution and enrichment.
By applying these cleansing, validation, and mapping routines as close to the data ingestion point as possible—for instance, when data is moved from external tables into more structured staging tables, or during the process of populating fact tables, data quality issues are identified and addressed early. This “shifts quality left” within the data pipeline, significantly reducing the likelihood of erroneous or inconsistent data propagating to downstream analytical systems and reports. This proactive approach not only minimises the cost and effort of data remediation later in the data lifecycle but also builds greater trust and confidence in the data warehouse as a reliable source for decision-making.
The following table summarises key Snowflake features and their relevance to an ID-First architecture:
Table 2: Key Snowflake Features for an ID-First Architecture
Snowflake Feature | Relevance to ID-First Architecture |
Universal ID (Conceptual) | The central MasterSecurityID acts as the primary key in DimSecurity, enabling unified data integration and simplified joins. |
Dimension Tables (e.g., DimSecurity) | Stores master data for securities, keyed by MasterSecurityID, including descriptive attributes and other standard identifiers (ISIN, FIGI) as attributes. Supports SCDs. |
Mapping Tables (e.g., SecurityIdentifierMap) | Crucial for linking various source system identifiers (SEDOL, CUSIP, proprietary tickers) to the MasterSecurityID. Maintained via automated/manual processes. |
External Tables | Facilitates ingestion of raw data from various sources (S3, Azure, GCS) with original identifiers before cleansing and mapping. Decouples ingestion from transformation. |
Python UDFs | Enables on-the-fly normalisation, validation (e.g., ISIN/FIGI checksums), fuzzy matching, and mapping lookups directly within SQL queries. |
Snowpark | Supports complex data transformations, advanced cleansing logic, and ML-based identifier matching using familiar DataFrame APIs in Python/Scala/Java. |
Star/Snowflake Schema Support | Snowflake’s relational capabilities fully support these dimensional modelling patterns, where DimSecurity (keyed by MasterSecurityID) is a central dimension. |
Time Travel | Allows access to historical states of data, invaluable for auditing changes to DimSecurity, mapping tables, and for recovering from accidental data modifications. |
Data Sharing (Secure Views) | Enables governed sharing of curated, ID-mastered security data with internal departments or external consumers, ensuring consistency. |
Dynamic Data Masking & Row Access Policies | Can be applied to tables/views derived from the ID-first model to protect sensitive attributes or restrict access based on user roles, even after data is unified. |
SQL Support (Joins, CTEs, Window Functions) | Robust SQL engine simplifies querying data once identifiers are unified, enabling complex analytics and reporting. |
Scalability & Performance | Separation of storage and compute allows scaling resources to handle large volumes of financial data and complex mapping/joining operations efficiently. |
Unlocking Value: Querying and Maintaining an ID-First Data Warehouse
Once an ID-First architecture is implemented in Snowflake, with a universal MasterSecurityID at its core, the benefits extend to simplified data querying, more effective deduplication, and robust data integrity.
A. Simplified Joins and Enhanced Analytics with a Unified ID
A primary advantage of the ID-First approach is the dramatic simplification of data joins. Instead of complex join conditions attempting to reconcile multiple, potentially inconsistent identifiers across tables, queries can consistently use the MasterSecurityID. For instance, joining a Fact_Holdings table (containing daily portfolio positions) with the DimSecurity table to retrieve descriptive attributes of the held securities becomes a straightforward join on MasterSecurityID.
Consider the following conceptual SQL query to retrieve the total market value per asset class for a specific portfolio on a given date:
SQL:
SELECT
ds.AssetClass,
SUM(fh.MarketValue) AS TotalMarketValue
FROM
Fact_Holdings fh
JOIN
DimSecurity ds ON fh.MasterSecurityID = ds.MasterSecurityID
JOIN
DimPortfolio dp ON fh.PortfolioID = dp.PortfolioID
WHERE
dp.PortfolioName = 'Frankfurt Equity Fund A'
AND fh.ValuationDate = '2024-12-31'
GROUP BY
ds.AssetClass;
In this example, the join between Fact_Holdings and DimSecurity is clean and unambiguous due to the shared MasterSecurityID. Without it, the join logic might involve a cascade of OR conditions checking for matches on ISIN, then SEDOL, then CUSIP, etc., leading to inefficient and error-prone queries. Snowflake’s SQL engine efficiently processes standard joins, and the simplicity afforded by a universal ID is a key tenet of effective star schema design.
The MasterSecurityID effectively becomes a stable “API contract” for all downstream data consumers, including analysts, reporting tools, and other applications. These consumers can build their queries, models, and processes relying on this single, consistent identifier for securities, irrespective of the multitude of source systems or source-specific identifiers that exist upstream in the data ingestion and mapping layers. This decoupling simplifies the development and maintenance of downstream analytical assets, making the entire data ecosystem more agile and less susceptible to breakage when upstream data sources change.
B. Effective Data Deduplication Strategies for Financial Instruments
Data deduplication, a common challenge in financial data management, is also significantly streamlined by an ID-First architecture. Once incoming data from various sources has been processed through the identifier mapping layer and each relevant record is associated with a MasterSecurityID, the primary challenge of identifying “what constitutes the same security” is largely resolved.
If multiple raw records from different feeds (or even within the same feed) resolve to the same MasterSecurityID, they are understood to represent the same underlying financial instrument. The task then shifts from complex, attribute-based fuzzy matching to a more straightforward process of selecting or consolidating records based on this master key. For example, when loading data into a staging area or a fact table, one might encounter multiple updates for the same security for the same day from different vendors.
Strategies can then be applied:
- Prioritisation: Choose the record from the most reliable source.
- Recency: Select the latest updated record.
- Merging: Combine attributes from multiple source records based on defined survivorship rules (e.g., take the price from Vendor A, but the rating from Vendor B).
Snowflake provides powerful SQL constructs like window functions (e.g., ROW_NUMBER()) that facilitate these deduplication strategies. For instance, to select the most recent unique record for each security before loading into a target table:
SQL:
WITH RankedIncomingSecurities AS (
SELECT
SourceSystemIdentifierValue, -- Original identifier from the source feed
SecurityName_Source, -- Name from source
AssetClass_Source, -- Asset class from source
--... other attributes from the raw feed
LoadTimestamp, -- Timestamp of when the record was loaded/received
mapping_udf(SourceSystemIdentifierValue, SourceSystemIdentifierType) AS MasterSecurityID, -- UDF call to get MasterSecurityID
ROW_NUMBER() OVER (
PARTITION BY mapping_udf(SourceSystemIdentifierValue, SourceSystemIdentifierType) -- Partition by the resolved MasterSecurityID
ORDER BY LoadTimestamp DESC, SourcePriority ASC -- Prioritise latest, then by source preference
) as rn
FROM
Staging_Raw_Security_Feed
WHERE
mapping_udf(SourceSystemIdentifierValue, SourceSystemIdentifierType) IS NOT NULL -- Ensure a MasterSecurityID was found
)
SELECT
MasterSecurityID,
SourceSystemIdentifierValue, -- Retain for lineage if needed
SecurityName_Source,
AssetClass_Source,
--... other attributes
LoadTimestamp
FROM
RankedIncomingSecurities
WHERE
rn = 1;
This query partitions the incoming data by the resolved MasterSecurityID and assigns a rank based on LoadTimestamp and a hypothetical SourcePriority. By selecting records where rn = 1, only one “best” record per MasterSecurityID is chosen for further processing or loading. This approach moves the deduplication challenge from complex, often unreliable record matching on multiple descriptive fields to a more deterministic process of master key consolidation. This significantly reduces the complexity and computational overhead associated with maintaining unique and accurate security data. It’s also crucial to implement validation rules and assign unique identifiers at the source where possible to prevent duplicates from entering the system in the first place.
C. Ensuring Data Integrity and Governance in an ID-First Model
The successful implementation and long-term viability of an ID-First data architecture hinge on robust data integrity and continuous data governance. This is not a “set and forget” solution; it requires ongoing attention and stewardship.
Key aspects of maintaining data integrity and governance include:
- Master Data Management (MDM) Principles: The DimSecurity and SecurityIdentifierMap tables are core MDM assets. Their accuracy, completeness, and consistency are paramount. This involves defining clear processes for:
- Creation of New Master Records: How new MasterSecurityIDs are generated and when.
- Updates to Attributes: How changes to security characteristics (e.g., name changes, reclassifications) are managed, including SCD logic.
- Lifecycle Management: Handling securities that mature, are delisted, or become obsolete.
- Data Quality Rules: Implementing automated data quality checks on DimSecurity and the mapping tables. This could include validating identifier formats, checking for referential integrity, ensuring consistency between related attributes (e.g., asset class and specific instrument type fields), and monitoring the age or confidence of mappings.
- Data Stewardship: Assigning clear ownership and responsibility for the DimSecurity and SecurityIdentifierMap tables. Data stewards are responsible for resolving mapping conflicts, validating new mappings suggested by automated processes, managing exceptions, and ensuring adherence to data quality standards. Tools like Snowflake Native Apps with Streamlit UIs can empower stewards in these tasks.
- Audit Trails: Maintaining comprehensive audit trails for all changes made to master security data and identifier mappings. Snowflake’s Time Travel can assist, but application-level logging of who made what change and why is also crucial for governance and regulatory compliance.
- Process for Handling New/Unmapped Identifiers: Establishing a defined workflow for when new, unrecognised identifiers are encountered in source feeds. This workflow should involve automated flagging, potential automated suggestions, and a clear path for steward review and approval.
- Access Control and Security: Implementing Role-Based Access Control (RBAC) to ensure that only authorised personnel can modify master data or mapping tables. Data classification should identify sensitive attributes, and appropriate security controls (e.g., dynamic data masking) applied if necessary.
The ID-First architecture is a living system. Financial markets are dynamic: new instruments are created, identifiers evolve, regulations change, and data sources are added or modified. Without continuous governance, clear ownership, and dedicated stewardship, even the best-designed ID-First model risks degrading over time, potentially becoming another source of data inconsistency. Therefore, organisations must commit to investing in the people, processes, and enabling technologies required to sustain the integrity and utility of their ID-First data warehouse.
Conclusion: Embracing an ID-First Future for Financial Data Engineering
The proliferation of inconsistent financial instrument identifiers presents a significant and persistent challenge for asset managers and fintech firms. As illustrated by the hypothetical Frankfurt asset management firm, this “data chaos” leads to operational inefficiencies, increased risk exposure, impaired decision-making, compliance hurdles, and stifled innovation. The traditional approach of reactively reconciling disparate identifiers is unsustainable in the face of increasing data volumes and complexity.
A. Recap of Benefits and Strategic Advantages
An ID-First data architecture, centred around a universal master identifier for securities and implemented on a modern cloud data platform like Snowflake, offers a strategic and robust solution. By prioritising a consistent, unique, and persistent identifier as the linchpin for all financial instrument data, organisations can achieve:
- Improved Data Quality and Consistency: Establishing a single source of truth for security master data.
- Enhanced Analytics and Business Intelligence: Enabling simplified data aggregation and more reliable insights.
- Increased Operational Efficiency: Reducing manual reconciliation and streamlining data integration.
- Stronger Data Governance and Compliance: Facilitating clearer data ownership, easier auditing, and improved regulatory reporting.
- Simplified and Agile Data Architecture: Reducing complexity and making the data ecosystem more adaptable to change.
The practical implementation within Snowflake involves designing dimension tables keyed by this universal ID, strategically using mapping tables for identifier reconciliation, leveraging external tables for flexible raw data ingestion, and employing Python UDFs or Snowpark for on-the-fly cleansing and validation. This approach not only addresses current data challenges but also builds a more resilient and future-proof data foundation.
B. Positioning AssetIdBridge as a Partner in Modernising Data Architectures
Successfully navigating the transition to an ID-First architecture requires specialised expertise in financial data, identifier management, and modern data platform technologies. Solutions and expertise, such as those offered by AssetIdBridge, can be instrumental in this journey. Whether through advanced identifier mapping tools, pre-built UDFs for validation of complex financial identifiers, or strategic consulting on data architecture design and MDM best practises, a knowledgeable partner can accelerate the implementation and help firms realise the full benefits of an ID-centric approach.
Final Thoughts
The journey towards a truly ID-First data architecture is a strategic commitment that extends beyond a mere technology upgrade. It requires a shift in mindset, a dedication to robust data governance, and cross-functional collaboration. However, for financial institutions aiming to thrive in an increasingly data-driven world, the long-term benefits, in terms of operational excellence, analytical prowess, risk mitigation, and competitive agility, are substantial and compelling. Embracing an ID-First future is an investment in clarity, consistency, and the enduring value of an organisation’s most critical data assets.
References
- www.bis.org, accessed on May 23, 2025, https://www.bis.org/ifc/development_and_maintenance.pdf
- Creating your first schema – JSON Schema, accessed on May 23, 2025, https://json-schema.org/learn/getting-started-step-by-step
- What is MDM (Master Data Management)? – Snowflake, accessed on May 23, 2025, https://www.snowflake.com/en/fundamentals/master-data-management/
- About CGS Identifiers – CUSIP Global Services, accessed on May 23, 2025, https://www.cusip.com/identifiers.html
- ISIN: What It Is, How, and Why It Is Used – Investopedia, accessed on May 23, 2025, https://www.investopedia.com/terms/i/isin.asp
- www.federalreserve.gov, accessed on May 23, 2025, https://www.federalreserve.gov/SECRS/2024/November/20241112/R-1837/R-1837_102124_161713_403678741308_1.pdf
- About the Financial Instrument Global Identifier® Specification …, accessed on May 23, 2025, https://www.omg.org/spec/FIGI/1.2/Beta1/About-FIGI
- www.fdic.gov, accessed on May 23, 2025, https://www.fdic.gov/federal-register-publications/aba-thomas-binder-supplemental-rin-3064-af96
- What is a Data Warehouse? | IBM, accessed on May 23, 2025, https://www.ibm.com/think/topics/data-warehouse
- What is Data Modelling? – Snowflake, accessed on May 23, 2025, https://www.snowflake.com/guides/data-modelling/
- Best practises for dynamic tables – Snowflake Documentation, accessed on May 23, 2025, https://docs.snowflake.com/en/user-guide/dynamic-tables-best-practises
- Introduction to external tables | Snowflake Documentation, accessed on May 23, 2025, https://docs.snowflake.com/en/user-guide/tables-external-intro
- Introduction to Python UDFs | Snowflake Documentation, accessed on May 23, 2025, https://docs.snowflake.com/en/developer-guide/udf/python/udf-python-introduction
- User-defined functions overview – Snowflake Documentation, accessed on May 23, 2025, https://docs.snowflake.com/en/developer-guide/udf/udf-overview